说明
若无特别说明,本文所涉及的代码版本为spring boot/cloud 2.2.6。
eureka server基本功能
-
接受服务注册
-
接受服务心跳
-
服务剔除
-
服务下线
-
集群同步
-
获取注册表中服务实例信息
若无特别说明,本文所涉及的代码版本为spring boot/cloud 2.2.6。
接受服务注册
接受服务心跳
服务剔除
服务下线
集群同步
获取注册表中服务实例信息
本文所分析代码版本为spring boot/cloud 2.2.6。
eureka中用到几个比较有意思的注解,简化程序实现。
表示从外部配置文件中(properties或是yml文件)读取”eureka.instance”对应的配置。
我个人觉得,学习源码的姿势,首先是需要知道想学习的框架/工具如何使用,然后接下来再去看源码注释,看看当时代码作者是如何阐述代码的,再去看代码怎么编写,效果才最佳。
同样的,接下来要分析的线程池,首先用途自不必说,不管有没有用过,ThreadPoolExecutor的运行机制、传说中的7个参数(核心线程数corePoolSize、最大线程数maxPoolSize、等待时间keepAliveTime、时间单位timeUnit、阻塞队列blockingQueue、线程工厂threadFactory、拒绝策略rejectHandler),相信大家都已经熟练掌握,此处不再赘述。
接下来简单过一下ThreadPoolExecutor的注释。
Continue reading »
本文所涉及spring/spring boot代码,请参考spring boot 2.2.6对应版本。
我们在刚学习spring boot时,有没有一个困惑:spring boot能够自动实例化很多第三方的依赖库?比如eureka、druid等。这个就涉及到spring boot的扩展机制spring factories。
简单来将,spring factories类似与Java SPI机制,利用该机制,我们能够自定义实现一些SDK或是spring boot starter,其实例化过程由我们来实现,使用方只需要在项目中引入包、不需要或是只需做很少的配置。
spring factories机制核心在spring-core包中定义的SpringFactoriesLoader类,该类的公有方法只有2个:
Continue reading »
本文基于Apache Kafka 2.5.1(2020.09.10拉取最新代码)
阅读源码前的首先要做到熟悉相关组件的概念、基本使用。而最靠谱的资料就是官方文档。
建议阅读官方文档(https://kafka.apache.org/documentation/)后,自己练习、使用kafka之后再开始阅读源码。 Continue reading »
提到Netty,就必须先说一下Reactor模式,源头应该是Doug Lea大神(学java的如果不知道这位神的请自己反思一下……)的Scalable IO in Java所提出的Multiple Reactors模式,参见下图
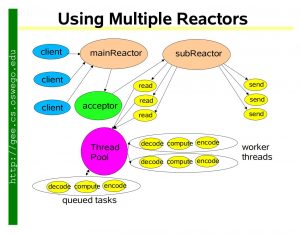
如果想知道为何出现Reactor模式,需要将IO发展过程,都说一下可能才会比较清晰,此处就不一一展开,有兴趣的童鞋可以参考这篇帖子: Continue reading »
学东西时我们应该尽量去看官网、看源码、看官方给出的单元测试。
比如Guava RateLimiter,从RateLimiter类的源码注释中可以看到,官方给出的典型应用场景与使用: Continue reading »